|
We propose a new framework for conditional image synthesis from semantic layouts of any precision levels, ranging from pure text to a 2D semantic canvas with precise shapes.
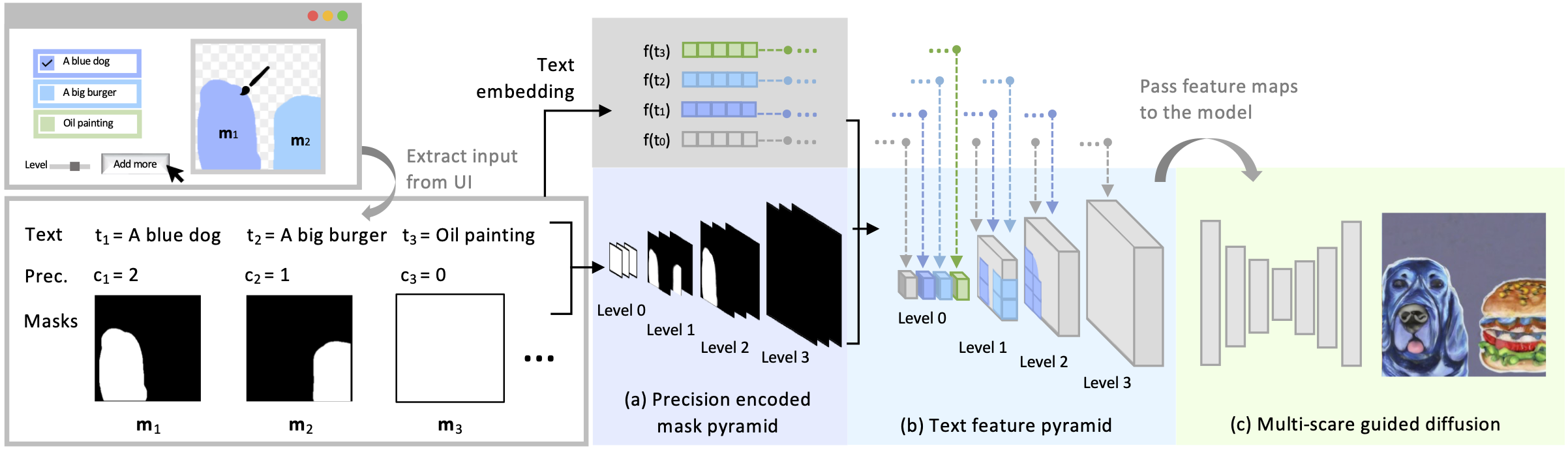
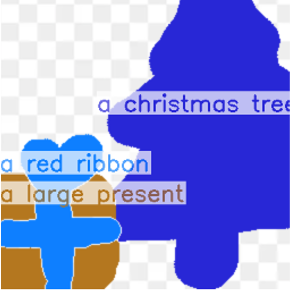
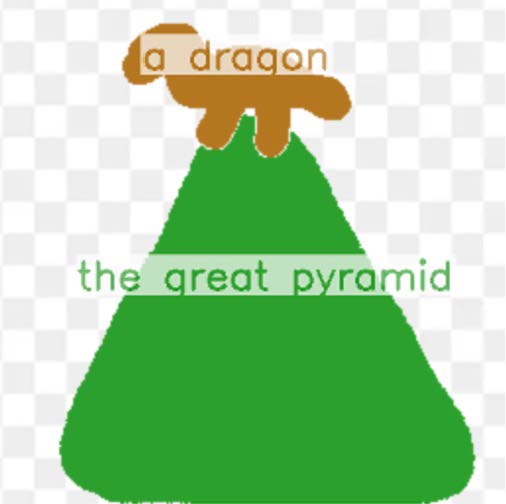
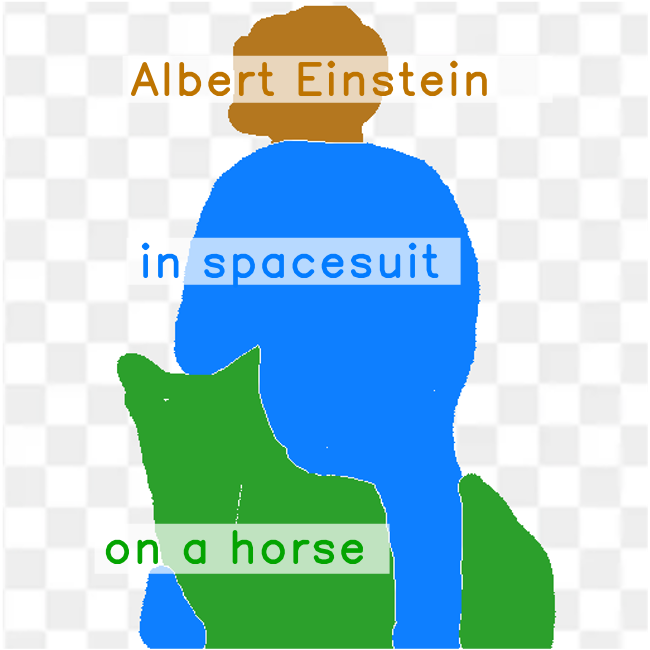
More specifically, the input layout consists of one or more semantic regions with free-form text descriptions and adjustable precision levels,
which can be set based on the desired controllability.
The framework naturally reduces to text-to-image (T2I) at the lowest level with no shape information, and it becomes segmentation-to-image (S2I) at the highest level.
By supporting the levels in-between, our framework is flexible in assisting users of different drawing expertise and at different stages of their creative workflow.
We introduce several novel techniques to address the challenges coming with this new setup, including a pipeline for collecting training data; a precision-encoded mask
pyramid and a text feature map representation to jointly encode precision level, semantics, and composition information; and a multi-scale guided diffusion model
to synthesize images. To evaluate the proposed method, we collect a test dataset containing user-drawn layouts with diverse scenes and styles.
Experimental results show that the proposed method can generate high-quality images following the layout at given precision, and compares favorably against existing methods.
|